
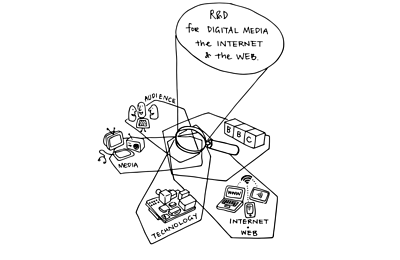
We are the Internet Research & Future Services group in ��ѿ��ý R&D, making new things on, for and with the internet.
There are roughly 25 of us now, a mixture of research engineers, software developers, UX designers and producers. We are just one of the groups in ��ѿ��ý R&D, with a focus on the internet and digital media and we are organised into 4 self-contained, fairly autonomous teams: Data, Discovery, Devices and Content. Each team has its own projects, although the teams often collaborate.
We have been writing weeknotes (less-accurately-named since we started writing them fortnightly) since . It started out as a good discipline, one of the things we like to do is work in the open.
But weeknotes might not always make sense to someone lacking context about our objectives and projects. Recently we put together some information about all the things we do for our new boss, and we thought we’d share what we could here, in addition to our regular update.
So, this is what we do — our current projects and recent progress.
Data Team
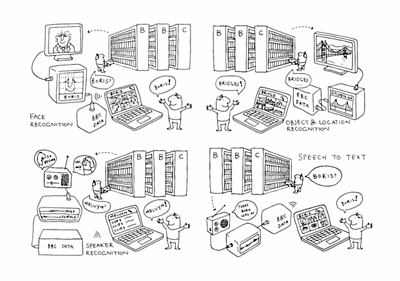
Our Data team’s internal motto is to make “Any half-remembered bit of TV or radio findable in 30 seconds or less”.
This starts with researching various facets of TV and radio metadata extraction, including speech-to-text for spoken content, face or voice recognition to find people, video fingerprinting to find similar footage, and more generally object recognition for visual searching. The technology solutions we come up with have application in production tools (to efficiently use assets, or as the basis for creative research), media asset management and possibly even audience-facing products.
Speech-to-text
The Data team has two major projects on at the moment. The first one - currently called the Speech Foundry - revolves around speech-to-text technology, and mainly aims to give the ��ѿ��ý a cost-efficient and accurate speech-to-text capability, as well as other features such as automated punctuation recovery and speaker identification. This follows on from our work with on extracting metadata from media at scale.
In recent weeks, we have seen some very promising results training a tool based on the open source Kaldi project. While Matt managed to train a full system using GPU-based machines on AWS (meaning we’re all set to start working on tweaks and improvements), Ben has been working on case and punctuation restoration to make the output of our speech-to-text system a bit more readable. It looks like he's found a method and we are ready to test it in a wider set of scenarios.
Digital Asset Management
The second project of the team, started late last year, is CODAM (Content Based Digital Asset Management) which endeavours to develop new technology and interfaces for visual search and fingerprinting. The early months were spent largely understanding the needs and experimenting with fundamental technology, but in the past few weeks our team started putting together a first iteration of a web tool, for which Chrissy built the interface and Jana came up with a database indexing scheme that so far improves the search speed by an order of magnitude. The IRFS team was treated to an impressive first demo last week, and we are now getting ready for user trials.
Discovery Team
The Discovery team’s aim is to help audiences find content and services which match or broaden their interests. To achieve this, we explore novel ways to help the ��ѿ��ý better understand audiences and content.
Content Analysis and Automated Tagging
A lot of the recent work done by the Discovery team has been around content analysis and especially automating semantic tagging, something which started as part of the COMMA and projects. The resulting automated tool, called Mango allows us to automatically tag any piece of text with DBPedia entities. Recently we have worked on increasing relevance and accuracy of the tool, as well as developing solutions for automatic recognition of entities (mostly people) which do not (yet) have an existing entry in Wikipedia/DBpedia.
Here’s Chris Newell describing his work in the past sprint or two:
Our Mango semantic tagging system can only recognise entities such as people, places and organisations that have their own Wikipedia page. This is a problem in the case of people because Mango will miss any mentions in documents tagged before they become sufficiently famous to gain a Wikipedia entry. To overcome this problem we've developed a system called Ramen that identifies names within documents so that it's possible to trace mentions of a particular individual without having to re-tag the entire document archive. As with any system based on natural language, problems arise due to ambiguities and inconsistencies but the initial results look very promising.
Armed with the sets of metadata which Mango generates, we have been working a fair amount on how we could use graph systems to discover interesting things about the content we analyse. We have been building graphs of entities (places, people, things) based on how and where they co-occur.
We will soon cover on this blog how our recent graph work has led us to visualisation-based exploration tools and algorithms to "broader the horizons" based on a specific set of interest - for now you can enjoy a small teaser with the illustration below.
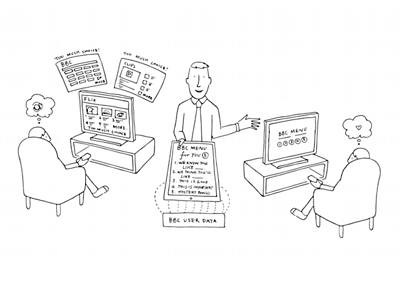
Recommendations and Sentiment Analysis
Other projects in the Discovery team have been looking at the audience and recommendations side of things - something with increasing importance as the ��ѿ��ý looks to make its services more personalised. A few recent projects have been using the Sybil recommendation models from the MyMedia project. The technology was used, for instance, to power the recommendations in the recent featured on ��ѿ��ý Taster.
We’ve also been experimenting with sentiment analysis. In particular, Peter, a trainee technologist, has been working on sentiment analysis and topic extraction for tweets matching ��ѿ��ý-specific keywords. Peter recently finished merging the two strands of his work into a single API, and has been using to create a web-based demonstrator.
Devices Team
Our Devices team works with connected devices: how to interact with them, build software for them, and how they affect our lives and media experience.
MediaScape
A lot of the Devices team’s current work is done within the - a collaborative project under the auspices of the EC for creating and refining developer-friendly standards for connected devices. In recent weeks the team used the Eurovision Song Contest as a use case, asking “How might we use connected devices to offer new experiences for groups enjoying the Eurovision Song Contest live at home?”. The result was a concept called “”.
Libby explains:
EuroMeme is the multi-device synchronised application we’re making to demonstrate some of the MediaScape technologies. The idea is that your tablet will sync up with the TV and enable you to make clips to share on the fly.
The team is now almost done building a web prototype working on an Android tablet. While Joanne analysed typical user interfaces for clipping video on mobile, other members were developing different components of the demo app: Dan made a media server for serving the main video and storing and making clips, Andrew worked on the front end tablet experience and Chris Needham has been developing the Android app, with generous help from Ant. The app has mDNS/DNS-SD support, so it can discover the TV on the local network. It then uses a web view that opens the clipping application, and so allows us to demonstrate the web-based sync by our MediaScape project partner Norut.
Cross-Platform Authentication
(CPA) is a project which grew out of previous work on RadioTAG, a bookmarking and resume feature for radio. CPA was developed as an authorization protocol suitable for devices with limit input and display capabilities, using OAuth 2.0 as a basis. Much of the work was done within MediaScape and the protocol, originally , is soon to be submitted to ETSI for standardisation. We also have a demonstrator showing how to add songs to your ��ѿ��ý Playlister account directly from a radio.
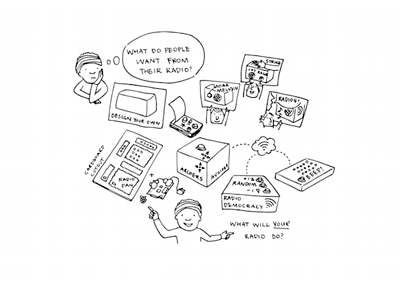
Radiodan
The was also founded under the auspices of MediaScape, but has developed into a project in its own right, exploring the shape of the product space around radio by talking to people about what they want from their radios, while also delving into the technology to understand the constraints and limitations of microservices for device control. This work has fed directly back into MediaScape, providing a modern control API for media devices based on our implementation experience.
Walls Have Eyes
Finally, in the “technology and society” side of things, the “” installation, first created for the Ethical Dilemma Cafe at the Mozilla Festival, is currently on display at the Design Museum in London, and we’ll be taking it out to dConstruct in Brighton in a couple of weeks. It is designed to make visible some of the data we unwittingly disclose whenever we move round physical space.
Content Team
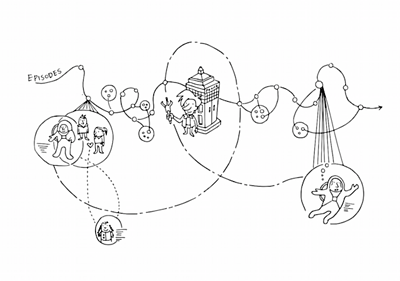
The Content team look at the new experiences and media that we could create across TV, radio and the web.
Atomised News
Our objective for this project, working with , is to develop a way of showing news stories on the web that makes them easier to understand. Initially we’re focusing on young people and mobile experiences. By “atomising” news stories into their component parts we are developing concepts that can show varying levels of detail and can be truly responsive to context and device.
Tristan describes the work so far:
Our first two complete prototypes took this in different directions. One is a mobile app that summarises a story on a “spine” of cards with the opportunity to dig deeper on certain aspects. The other is a video-based app that uses chapterised videos and gives options to insert more video on particular aspects as you’re watching. Both prototypes tested well and we are now taking the best aspects of each onto the next stage of prototyping. We are working closely with ��ѿ��ý News Labs on how to use their concepts of to power these experiences in an efficient and re-usable manner and with journalists on how to best tell their stories.
In recent weeks, the team have been working to redesign the way we atomise news, moving towards a "Storylines, events, people & places" model instead of a content-driven "images, videos, text" definition of atoms. This will allow better integration with News Labs and more powerful connections between atoms to be made, but requires limiting the way stories can be written.
��ѿ��ý Front Story Explorer
“If you just want a quick catch-up [...] it was to the point, snappy.”
This is a that explores the concept of something that better supports drama on the web. There’s more and more scripted drama on TV and radio and it’s getting longer and more complex. The aims to provide recaps and catch-up beyond watching the whole programme and also lets people explore deeper to get a better understanding of what happened in the story. We built a proof-of-concept prototype based around characters, storylines and moments of the Radio 4 daily serial, ��ѿ��ý Front. We aimed to find out if there is an audience appetite, who it’s most suited for and which features are most important.
��ѿ��ý Front has now been on Taster for two months and we’ve had a great response from people, now we’re looking at analytics data and the results of a more specific user study to see what we’ve learnt. It seems to have proved useful for catch-up and recap for both existing and new listeners, the storyline and character focus is right and the text plus media presentation works for both skimming and recapping.
Storyarc
We’ve also been developing a new continuity database for drama teams, something they can use for keeping track of what’s happened and who’s done what. We’ve been working with the Archers and ��ѿ��ý Front teams to do this and our vision is for a single common data model that supports production tools and audience-facing services. In this case we have used Storyarc to provide all the data about storylines, moments and characters that powers the ��ѿ��ý Front Story Explorer.
Immersive journalism
We have been exploring 360 degree filming with news to understand how to use this new technology and its implications for journalism. We went to the migrant camp in Calais and using a 360° filming rig for dramatic and chaotic scenes with migrants, police and lorries revealed a number of challenges with the kit. But we managed to turn around three clips, and publish them on the ��ѿ��ý News Labs YouTube Channel. We’re continuing this work to produce a body of 360° journalistic content to enable ��ѿ��ý stakeholders to better understand the possibilities of VR journalism and to facilitate audience testing.
Get in touch!
We hope this re-introduction to all of the current projects of IRFS (which is only a small portion of all our R&D work!) will make it easier to follow our weeknotes. Was it useful? Any project you'd like to hear more about? Get in touch with us on twitter: .
(illustrations for IRFS and the four teams by )
Search by Tag:
- Tagged with Weeknotes Weeknotes