
The internet has had a relatively brief existence, yet it has already had a huge cultural impact on us. Preserving it for historical reasons is very important as it is such a massive part of the modern world. However, the internet and the content accessed through it have a big problem - it is short-lived. A website available today might not be available tomorrow. One study found that - which is astonishing.

This is not a new problem. Services such as the and others have been automatically capturing the internet for many years, giving users the ability to play back historical sites. However, capturing website content from outside an organisation doesn't always produce an accurate representation of a website.
The capturing process these services take is to use something called a web crawler. This crawler visits each page that needs capturing and stores the request to and response from the site. It then follows any links it can find in the web page to other pages or assets. As a result, it works its way through by capturing pages, images, videos, style-sheets, and anything else it thinks it needs to render the page correctly. All of these resources are then bundled into a standardised file format, called a . Capturing into this format ensures playback is possible in the future, regardless of the state of the internet.
Archiving StoryKit experiences - challenges
StoryKit is a set of tools for giving content creators the ability to make responsive experiences and deploy them via the internet. One of the areas I have been looking at recently is how to archive the . I've chosen this area as sometimes we are so focused on moving technology forward that we don't think about preserving what we have already created. Will these early web-based object-based media (OBM) exemplars be able to be viewed in 5, 10 or 50 years in the future? The answer is a resounding no, at least not without effort from us.
- ��ѿ��ý Taster - Try Click's 1000th Interactive Episode
- ��ѿ��ý Radio 4: Today - Try the New Radiophonic Travel Agency
- ��ѿ��ý Taster - Try His Dark Materials: Discover Your Dæmon
The ��ѿ��ý already has a web archiving strategy to actively capture the ��ѿ��ý website, and this works very well for most of the ��ѿ��ý's existing online portfolio. However, experiences in StoryKit use modern web technology that traditional web crawlers will find difficult or impossible to archive correctly. As a result, they need a different strategy.
There are a few reasons as to why this is the case. The first problem we have is that our experiences are often branching. This means that not all the resources are loaded when the page is loaded. The resources are instead loaded via Javascript when needed. As a result, the crawler needs to be able to walk through the website to understand what assets need to be captured. However, this is difficult as a web crawler would have to interpret the Javascript and interact with the content.
The second problem is that sometimes the number of branching paths is impractical even for a computer to follow. , for example, had 84 quadrillion paths.
- Thanks to everyone who guessed at how many unique programmes you could create through @��ѿ��ýClick 1000. Most popular guess, 84 trillion. Correct answer: there are 84 quadrillion different (legal) paths through, from beginning to end. How many have you tried? — Spencer Kelly (@spenley) July 8, 2019
Another big problem that the crawler will encounter is the streaming media formats we use, such as Dynamic Adaptive Streaming over HTTP (DASH) and HTTP Live Streaming (HLS). First, if the crawler presents itself as an Apple browser, it'll only capture HLS. As a result, only Apple browsers will be able to play back the archive. Similarly, if the crawler presents itself as a non-Apple browser, then it'll only capture DASH. This again results in the archive only working on some devices.
The crawler will also have issues with the adaptive nature of these DASH and HLS formats. This is because the browser fetches segments of media based on the client's bandwidth. So if the crawler has a different bandwidth to the user replaying the archive, it will not play back correctly.
- ��ѿ��ý R&D - StoryKit: An Object-Based Media Toolkit
- ��ѿ��ý R&D - StoryFormer: Building the Next Generation of Storytelling
StoryKit's unique archiving strategy
As I've shown, there are several issues with capturing StoryKit experiences. We, however, have the original source code and assets for each experience. Using these resources, we have created a tool and strategy to capture these experiences much more effectively than any standard archiving tool whilst still capturing them into WARC format.
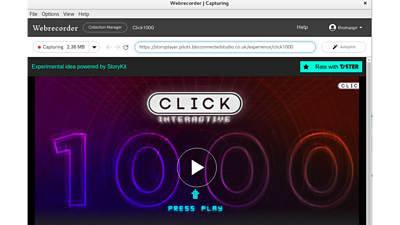
The capturing strategy is as follows:
- First, we try to capture the experience using a tool called The result of this tool, however, is usually an unplayable website. This is not an issue as we use the produced WARC as a base for the rest of the process.
- Next, using the framework, we inject the static assets from the website into the WARC. This makes sure that the WARC has assets such as play/navigation buttons or share icons captured in it. Not performing this step results in the archived experience missing controls, making it unplayable.
- After this, we inject the experience specific assets into the WARC. We again use the framework. The key point here is that instead of injecting DASH or HLS, we instead inject web-safe MPEG files. We can do this as we have the source media material.
- Finally, we update the metadata in the captured HTML to load the experience assets we injected earlier instead of the original media. To do this, we use our knowledge of StoryKit's data model and how the code works.
This strategy solves the problems mentioned above. Firstly, by using the WARC format, we have ensured compatibility with existing and future web archiving tools. Secondly, as all media needed is injected automatically, the need for the crawler to interact with the experience or understand Javascript is removed. Finally, by replacing DASH and HLS with standard media files, we have removed the need to worry about how to capture those formats.
As the web increasingly moves towards Javascript web applications that dynamically load assets, web crawlers will find it difficult to record an accurate copy of a website. As a result, it will be up to those websites' creators to help capture them by using their knowledge of their source code and assets. I believe the above approach of taking a standard web capture and augmenting it with missing assets may prove to be a useful strategy in the future.
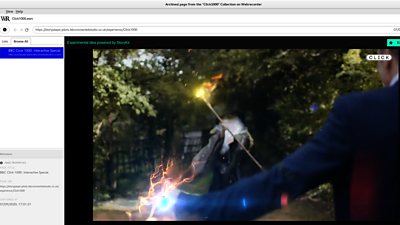
Ultimately, we can now accurately save any experience designed with StoryKit into a WARC file and pass it to ��ѿ��ý Archives for long-term storage. These archives can then be played back with web archiving tools, as shown in the above image. This allows us to ensure experiences can be played back in many years, long after StoryKit ceases to exist.
- -
- ��ѿ��ý R&D - StoryKit: An Object-Based Media Toolkit
- ��ѿ��ý R&D - Making a Personalised, Data-Driven Documentary
- ��ѿ��ý R&D - Where Next For Interactive Stories?
- ��ѿ��ý R&D - Storytelling of the Future
- ��ѿ��ý R&D - StoryFormer: Building the Next Generation of Storytelling
- ��ѿ��ý R&D - Delivering Object-Based Media at Scale with Render Engine Broadcasting
Search by Tag:
- Tagged with Archives Archives
- Tagged with IP Production and Broadcast IP Production and Broadcast
- Tagged with Content Formats Content Formats
- Tagged with Internet Internet
- Tagged with Personalisation Personalisation
- Tagged with Interactivity Interactivity
- Tagged with Immersion Immersion
- Tagged with User Interfaces User Interfaces
- Tagged with Audio Audio
- Tagged with Video Video
- Tagged with Features Features